Duplicate Scrobble Guidance
Multi-scrobbler's flexibility in configuration allows you to build some complex pipelines for scrobbling but it can also be a footgun for duplicating scrobbles.
How Duplicates Are Detected
Multi-scrobbler uses multiple techniques for evaluating the similarity of text in scrobbles against existing data.
These techniques are used on all text from a scrobble (title, artist, album...):
Character and string normalization
Symbols and multiple whitespaces are removed. All characters are converted to lowercase. Non ascii characters are converted to their ascii counterparts.
this string! is the. same => this string is the same
this string is the same => this string is the same
ThIs STRING iS THe SAMe => this string is the same
Dina Ögon => Dina Ogon
Nanã => Nana
Word-order invariant text similarity
Strings with multiple words (tokens) are re-arranged so that tokens are ordered to be as close to other, similar tokens are possible:
Example 1
String A: there change is => there change is
String B: there is change => there change is
Example 2
String A: you, doin hwat are => you doin hwat are
String B: what are you doing => you doing what are
Then, the strings are independently compared using Levenshtein Distance and Dice's Coefficient. The algorithm that gives the highest score for similarity is used so that matching is aggressive.
For Artists, Multi-scrobbler attempts to extract unique Artists from common patterns in single-string artist values and track titles.
Matching Common Artist Patterns
Common joiners and patterns are detected in artist/track strings and the artists are extracted. Example of common joiners are: ft. feat vs. etc...
Example 1
Melendi, Ryan Lewis, The Righteous Brothers (featuring Joan Jett & The Blackhearts, Robin Schulz)
becomes
Melendi, Ryan Lewis, The Righteous Brothers, Joan Jett, The Blackhearts, Robin Schulz
Example 2
Childish Gambino - 12.38 (feat. 21 Savage, Ink & Kadhja Bonet)
becomes
Childish Gambino, 21 Savage, Ink, Kadhja Bonet - 12.38
- MS uses "smart" heuristics to prevent artists with actual punctuation (
Tyler, The Creator) from accidentally being separated - The extraction examples above are done only for matching other scrobble data (which is also parsed like the above), the resulting scrobble data is never transformed unless the user explicitly configures it via a native transform
The timestamps for Scrobbles are compared at different levels of granularity based on where they originate from.
Temporally Comparing Scrobbles
Timestamp closeness for two scrobbles can be classified in one of these states:
Exact
Timestamps differ by 1 seconds or less.
Close
Timestamps differ by less than the known granularity of the Source they are from. For most Sources (and all Clients) this is 10 seconds or less. For some sources (subsonic) the granularity is 60 seconds because they only report "now playing" changes every 60 seconds.
During
If the Play was monitoring in real-time by Multi-scrobbler then it knows the time range during which the Play was listened to. If an existing scrobble with similar artist/track/album has a timestamp that occurred during the known listening time then it is classified as during.
Fuzzy
If the timestamp occurs within a few seconds +/- of (existing scrobble + track duration) then, potentially, the Source timestamped the existing scrobble at the end of when the user listened to it, rather than when the user started listening to it. This is common for Spotify plays.
Each of the above classification results in a different score that is roughly descending from the order given above. Exact score is based on the Souce of the scrobble and if it was monitored in real-time by Multi-Scrobbler.
Finally, all of the above comparison/normalization techniques are combined when comparing a "new" Play/Scrobble against existing data. Each comparison is given a weighted score. If the score is above the match threshold then it is marked as a duplicated.
Match Scoring Example
Frédéric Chopin - Ballade No. 4 in F Minor, Op. 52 @ 2026-05-04T13:01:51-04:00 <-- New scrobble
Frédéric Chopin / Krystian Zimerman - Ballade No. 4 in F Minor, Op. 52 @ 2026-05-04T13:01:48-04:00 <-- Existing scrobble from client
After comparing against all existing scrobbles from the client, in a timerange around the new scrobble, MS finds a match and logs the match along with the score breakdown of the consistuent parts:
Source:
Frédéric Chopin - Ballade No. 4 in F Minor, Op. 52 @ 2026-05-04T13:01:51-04:00 (S)
Closest Scrobble:
Frédéric Chopin / Krystian Zimerman - Ballade No. 4 in F Minor, Op. 52 @ 2026-05-04T13:01:48-04:00 (S)
Artist: (0.30 + Whole Match Bonus 0.52) * (0.3 + Whole Match Bonus 0.05) = 0.29
Title: 1.00 * 0.4 = 0.40
Time: (Close) 1 * 0.5 = 0.50
Time Detail => Existing: 13:01:48-04:00 - Candidate: 13:01:51-04:00 | Temporal Sameness: Close | Play Diff: 3s (Needed <10s) | Range Comparison N/A
Score 1.19 => Matched!
All of the above techniques and scoring gives Multi-scrobbler a very good chance of detecting duplicate scrobbles, regardless of where they were originally from. Of Multi-Scrobbler's 400+ unit tests, 70+ are related to testing scoring, artist extraction, and fuzzing string normalization/simiarlity.
The dupe detection is so good that it is virtually gauranteed for most configurations and is used for backlogging missed scrobbles for Sources that support fetching history.
However, it's not possible to gaurantee this for all possible Multi-scrobbler configurations. See the below sections to learn more.
Configurations Where Duplicates DO NOT Occur
- Any Source/Client configuration where there is only one Source and one Client and they are not the same service/account
- Any Source/Client configuration where scrobbles only flow in one direction
- IE you do not have a Last.fm Client Account A that is also a Last.fm Source Account A
The majority of simple Multi-scrobbler configurations fall into these categories. If your workflow is straightforward you do not need to worry about duplicates at all.
Multi-scrobbler can handle recieving the same data from a Source multiple times. This is fine because the data is always the same and always unique to each Source. Since MS scrobbled the data to your clients you can be pretty confident that the same cleanup/matching process for that data will result in an indentical/similar match to the existing scrobble.
IE Same inputs in -> same inputs out.
Even this scenario with multiple, mixed Sources is OK:
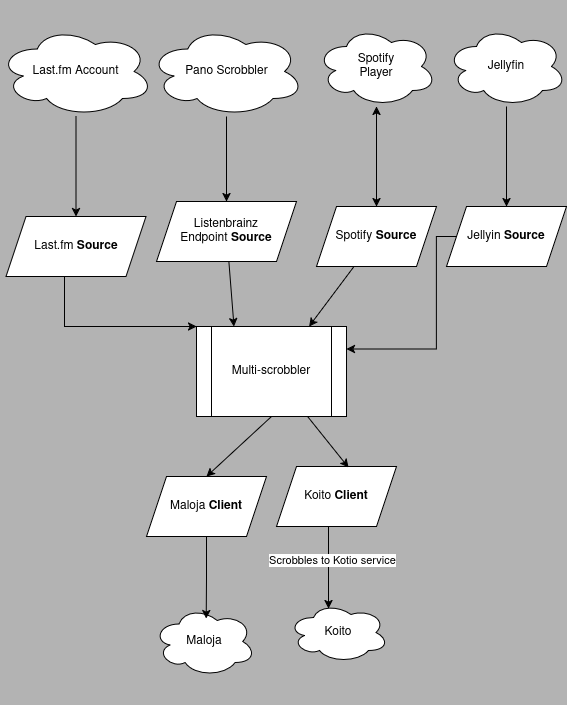
Because the scrobbles coming from each Source are independent of each other. And they end up in Clients that are not also used as Sources.
This is a common scenario when scrobbles are backlogged from a Source IE on startup MS fetches the last 50 Plays from Spotify/Lastfm/Listenbrainz.
Configurations Where Duplicates CAN Occur
Upstream Scrobbles Sent to Multiple Sources
In this scenario your device using Spotify is configured in MS as a Spotify Source but it also is scrobbling to Last.fm (via Pano Scrobbler, as an example).
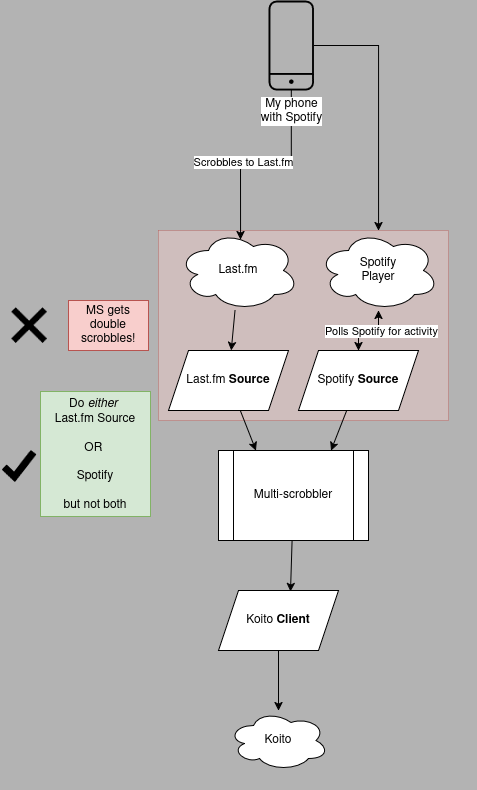
❌ Time Race Condition: Potentially, the scrobbles arrive in Multi-scrobbler at exactly the same time. There are no existing scrobbles in Koito to check against, yet. So Multi-scrobbler scrobbles both to Koito, resulting in duplicate scrobbles.
❌ Different Scrobble Data: Pano Scrobbler, or Last.fm, may modify the scrobble data. When MS recieves the scrobble from Last.fm it may be just different enough that it does not get detected as a duplicate.
Sources and Clients are Dependent
In this scenario, you have a Client that is also a Source and that Source is feeding scrobbles to a different Client that receives scrobbles from everywhere (or has some overlap with the original Client).
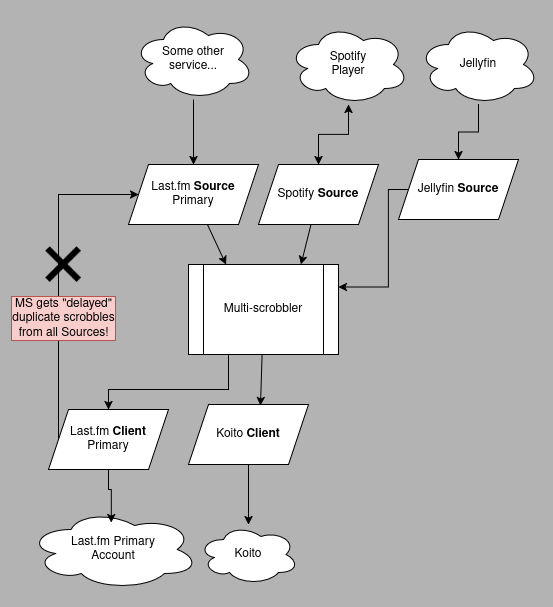
❌ Different Scrobble Data: Last.fm may modify the scrobble data. When MS recieves the scrobble from Last.fm it may be just different enough that it does not get detected as a duplicate.
❌ Consistency Issues: If the Koito Client has a backed up queue or is not currently scrobbling (imagine it was Last.fm or Listenbrainz, and they had upstream availability issues), then there is no existing scrobble yet and nothing to match against.
Configuration Solutions to Avoid Duplicates
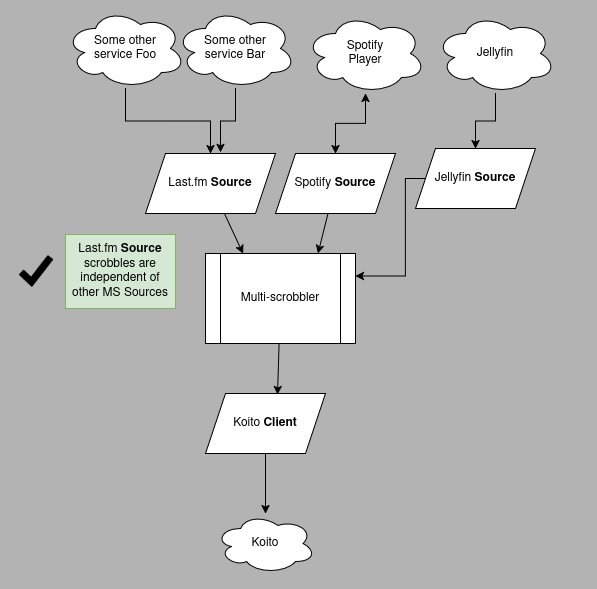
Independent Sources
Use a configuration mentioned in Configurations Where Duplicates DO NOT Occur: make sure all of your Sources are independent. The activity/scrobbles from each Source do not have any upstream duplicates of activity.
Alternative Sources
Imagine you have a scenario where a device/player can only scrobble to Last.fm. But you want to use MS for all other devices/sources and still have all your scrobbles end up in your "main" Last.fm account for social reasons/stats.
Instead of using the same Last.fm account for all activity and potentially having dependent client/sources, create an additional last.fm account that is used only for the device that needs it. This ensures the scrobbles from that device are isolated from the main account and do not prevent duplicates, so you can continue to use the main account as an MS Client:
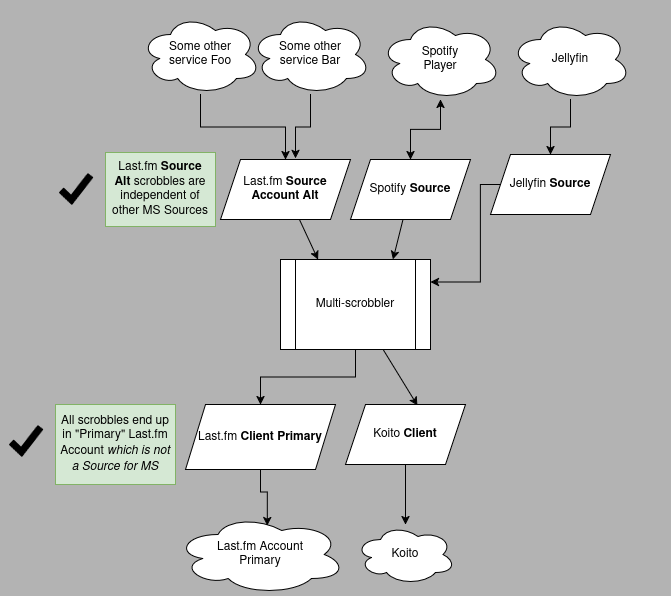
Mirror-Only Clients or Limiting Scrobble Destination
In Multi-scrobbler, by default, all Sources scrobble to all Clients. Using Limit Scrobble Destinations configuration can ensure that your dependent Source/Clients only scrobble to destinations where the scrobbles won't be duplicated. And/or limit other Sources to not scrobble to dependent Sources/Clients.
Here is an example where all Sources only scrobble to a dependent Last.fm Client, and then the dependent Last.fm Source only scrobbles to a "mirror-only" (backup) Koito Client:
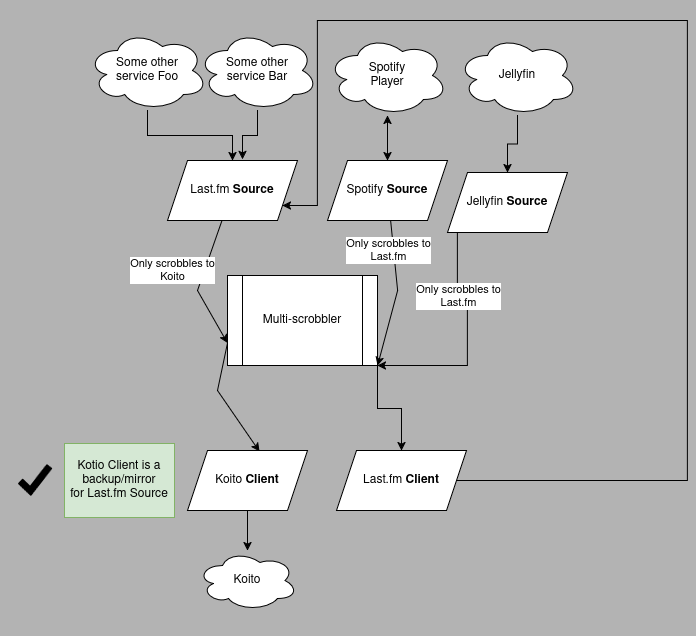
Normalize All Scrobbles
If using one of the above solutions is not possible you can also try to aggressively normalize all scrobble data using the Musicbrainz transform stage.
In this scenario you still have dependent Source/Clients that are not isolated but you can potentially improve duplicate detection by first using a transform stage to match scrobbles against the Musibrainz database and normalize their track/artist/album data.
There is no gaurantee this will work but it is better than nothing. You should attempt to re-configure MS to use any of the other solutions before using this one.
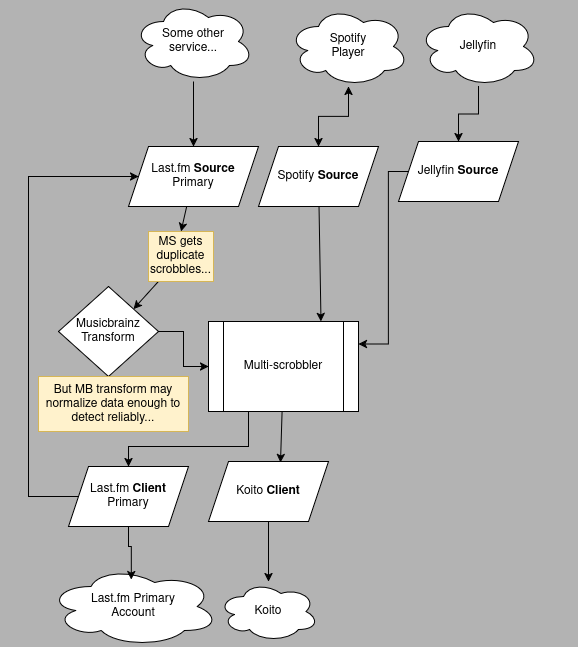
The Last.fm Problem
Last.fm will happily accept almost any scrobble data you throw at it.
It can then decide, opaquely, to match or modify that scrobble to some more "official" data it has server-side. This could be modifying the artists, title, or album sent in the scrobble. It can also mean modifying the mbid (unique identifier) or adding what it thinks is the correct one.
There is nothing in the scrobble history API response from Last.fm that identifies it has done any of this. And it's not super great at being right about these modifications.
What this means for you, the user, is that this is very plausible scenario:
- You scrobble
Artist Foo, Artist Bar - My Cool Trackto Last.fm via Pano Scrobbler (outside of Multi-scrobbler)- Last.fm modifies the data to
The Artist Foo - My Cool Track ft. Artist Bar (Album Version)
- Last.fm modifies the data to
- You also scrobble
Artist Foo, Artist Bar - My Cool Trackto Multi-scrobbler via Pano LFM endpoint Source- MS forwards this to Koito Client as-is
- Soon after, MS polls your Last.fm Source for new scrobbles and finds
The Artist Foo - My Cool Track ft. Artist Bar (Album Version)- It queries Koito to see if this was scrobbled
- It sees that a scrobble did happen at almost the same time BUT the track titles and artist strings are just different enough that it decides it's not a duplicate
- MS forwards the scrobble to Koito and you now have a duplicate
This behavior is unique to Last.fm. It's truly the worst out of all the scrobbler services in terms of preserving your data as-is, or providing a unqiue identifier for your data.